
44,5 milliards de dollars. C'est le montant du gaspillage cloud projeté pour 2025 au niveau mondial, selon une étude récente de Harness. En cause : un décalage entre les équipes FinOps et les développeurs, et une visibilité quasi nulle sur l'utilisation réelle des ressources. Dans le monde de la data analytics, ce phénomène est tout aussi présent : les pipelines tournent à vide, les modèles se reconstruisent inutilement, et les factures cloud explosent sans que personne ne comprenne vraiment pourquoi.
FinOps n'est pas un programme d'austérité budgétaire. C'est une discipline qui vise à créer une culture de responsabilité partagée autour des dépenses technologiques, en reliant systématiquement la dépense à la valeur métier. Et dans cet univers, dbt émerge comme un allié stratégique pour installer une gouvernance durable des coûts data.
Qu'est-ce que le FinOps, vraiment ?
Selon la FinOps Foundation, le FinOps est une pratique de gestion financière du cloud qui permet aux organisations de tirer la valeur métier maximale de leurs investissements technologiques. Cette discipline repose sur six principes fondateurs :
Les équipes doivent collaborer — ingénierie, finance et métier travaillent ensemble.
Les décisions sont pilotées par la valeur métier — pas par la réduction budgétaire aveugle.
Tout le monde assume la responsabilité de son usage — fini les dépenses invisibles.
Les rapports FinOps doivent être accessibles et opportuns — visibilité en temps réel.
Une équipe centralisée pilote le FinOps — avec un mandat clair d'optimisation.
Profiter du modèle de tarification variable du cloud — flexibilité et adaptation.
Le FinOps se déroule en trois phases itératives : Informer (visibilité et allocation des coûts), Optimiser (identification des opportunités d'efficacité) et Exploiter (mise en œuvre des changements et amélioration continue). La maturité se mesure selon un modèle Crawl → Walk → Run, où chaque organisation progresse à son rythme en fonction de ses besoins métiers.
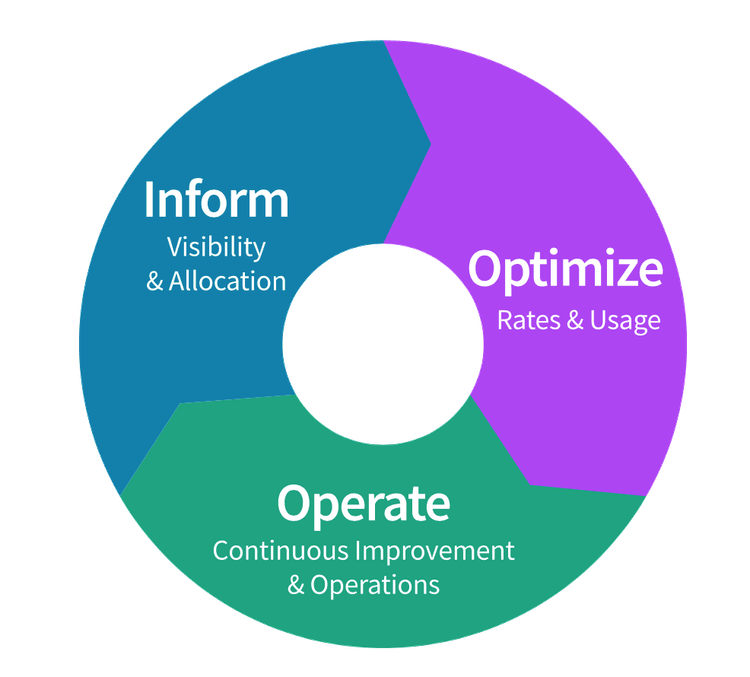
Selon le State of FinOps 2025, l'optimisation des workloads et la réduction du gaspillage restent la priorité numéro un pour 50 % des praticiens FinOps. Mais la tendance de fond, c'est l'extension du FinOps au-delà du cloud public : 65 % des équipes gèrent désormais le SaaS, 48 % le datacenter, et 63 % (contre 31 % l'an dernier) pilotent déjà les coûts liés à l'IA.
Pourquoi les coûts data dérapent systématiquement
J'ai accompagné suffisamment de migrations cloud pour identifier quatre patterns qui reviennent systématiquement :
1. Zéro visibilité granulaire
Les plateformes cloud fournissent des factures agrégées par warehouse ou cluster, mais rarement par modèle ou par pipeline. Résultat : impossible de savoir si ce modèle gold_customer_analysis qui coûte 10 € par run alimente vraiment un rapport CFO critique ou s'il tourne à vide depuis des mois.
2. Dépense déconnectée de la valeur
Un pipeline peut consommer 8 € par run pendant six mois sans qu'aucun consommateur en aval ne consulte les données produites. Sans lineage documenté, difficile de faire l'arbitrage entre ce qui crée de la valeur et ce qui relève du gaspillage pur.
3. Responsabilité floue
Qui est propriétaire de ce modèle ? L'équipe data ? L'équipe finance ? Le métier ? Lorsque personne n'assume explicitement la responsabilité d'un asset, personne ne le challenge non plus. Et les coûts continuent de grimper.
4. Ressources mal dimensionnées
Les jobs dbt se lancent souvent avec une config par défaut qui reconstruit l'intégralité du DAG, même quand seuls 10 % des modèles ont changé. Conséquence : des runs qui durent 3h30 au lieu de 25 minutes et des factures warehouse qui triplent sans raison valable.
Les leviers dbt qui transforment réellement une démarche FinOps
Quand on parle de FinOps dans la data, le sujet est souvent réduit à la réduction des coûts cloud.
Mais en pratique, optimiser une plateforme data ne consiste pas uniquement à “dépenser moins”.
L’objectif est surtout de :
éviter les traitements inutiles,
améliorer l’efficacité opérationnelle,
donner de la visibilité sur les usages,
et relier les coûts à la valeur métier réelle.
C’est précisément là que dbt Labs apporte une vraie différence.
Au-delà du framework de transformation SQL, dbt introduit plusieurs mécanismes qui permettent d’industrialiser une démarche FinOps directement dans les workflows analytics.
1. Slim CI : ne reconstruire que ce qui a changé
Dans beaucoup d’équipes data, chaque pull request déclenche la reconstruction complète des pipelines dbt :
la majorité des modèles n’ont pas changé
les warehouses sont sollicités inutilement
les temps de validation explosent
Avec le mécanisme Slim CI, dbt compare l’état actuel du projet avec le dernier état validé en production.
Résultat :
seuls les modèles réellement modifiés sont reconstruits,
les dépendances impactées sont ciblées automatiquement,
les environnements de CI deviennent beaucoup plus légers.
L’intérêt FinOps est immédiat :
✅ moins de compute consommé
✅ pipelines plus rapides
✅ meilleure expérience développeur
L’enjeu n’est pas seulement économique : c’est aussi une optimisation globale de la vélocité engineering.
2. State-Aware Orchestration : arrêter les runs inutiles
Dans beaucoup de stacks data, les pipelines tournent selon une logique purement temporelle :
toutes les heures,
toutes les 30 minutes,
ou plusieurs fois par jour.
Le problème est simple :
les données sources n’ont souvent pas changé.
Pourtant, l’intégralité des modèles est recalculée à chaque exécution.
Avec la logique de State-Aware Orchestration, dbt introduit une approche beaucoup plus intelligente :
avant de relancer un modèle, le moteur vérifie :
si le code a changé,
si les données upstream ont été modifiées,
et si une reconstruction est réellement nécessaire.
Si rien n’a évolué :
➡️ le modèle est réutilisé
➡️ aucun recalcul n’est déclenché
Cette approche change profondément la logique FinOps :
on passe d’une orchestration “par habitude” à une orchestration pilotée par l’état réel des données.
Les bénéfices sont multiples :
réduction drastique du compute inutile,
amélioration des temps de run,
baisse de la pression sur les warehouses,
meilleure prévisibilité des coûts.
3. Cost Insights : rendre enfin les coûts visibles
L’un des plus gros problèmes FinOps dans la data reste la visibilité.
Très souvent :
les équipes voient une facture globale Snowflake/Databricks,
mais personne ne sait réellement quels modèles coûtent cher,
ni quels usages métier justifient ces dépenses.
Avec Cost Insights dans dbt Labs, les coûts deviennent enfin lisibles au niveau :
des jobs,
des projets,
et des usages métier associés.
L’intérêt est majeur :
vous ne pilotez plus uniquement des infrastructures,
vous pilotez des coûts reliés à la valeur business.
Cela permet notamment :
d’identifier les pipelines coûteux mais peu utilisés,
de responsabiliser les équipes data,
de prioriser les optimisations les plus utiles,
et d’arbitrer les dépenses avec des métriques concrètes.
Le FinOps devient alors un sujet partagé entre engineering, analytics et métier, plus seulement un sujet “infra”.
Le lineage : la pièce maîtresse du FinOps moderne
Le vrai apport de dbt dans une démarche FinOps n’est pas uniquement technique.
C’est sa capacité à connecter :
➡️ la dépense technique
➡️ aux usages métier réels
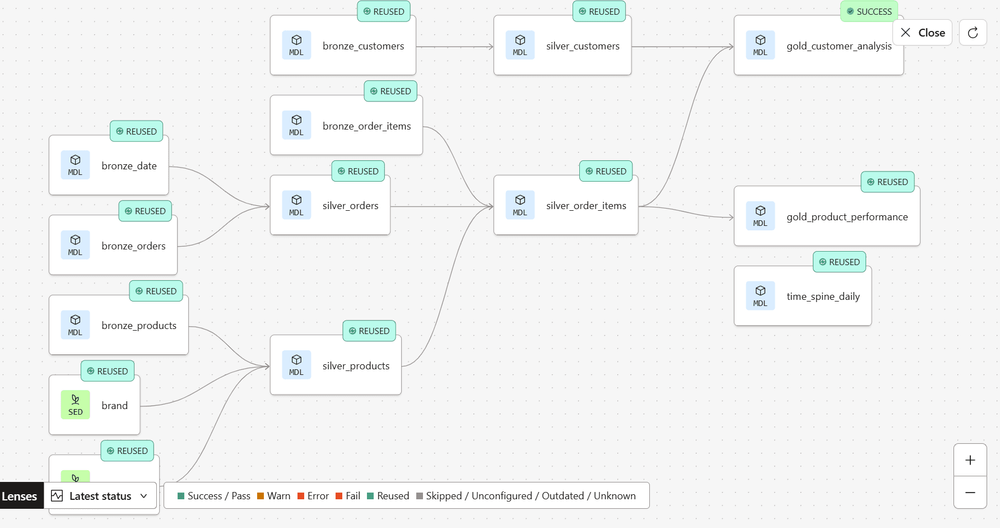
Grâce au lineage, il devient possible de comprendre immédiatement :
quels dashboards dépendent d’un modèle,
quels pipelines alimentent des reportings critiques,
et quels traitements tournent sans aucun consommateur réel.
Sans cette visibilité, impossible de distinguer :
un coût stratégique,
d’un simple gaspillage compute.
Le lineage transforme donc le FinOps :
on ne cherche plus uniquement à “réduire les coûts”,
on cherche à optimiser la valeur produite par chaque traitement data.
Le coût caché du debugging sans lineage
Le coût d’une plateforme data ne se limite jamais à la facture cloud.
Le véritable enjeu apparaît souvent ailleurs : dans l’inefficacité opérationnelle du quotidien.
Un pipeline qui casse sans visibilité claire, un dashboard incohérent à investiguer, plusieurs équipes mobilisées pour retrouver l’origine d’une anomalie… Ces situations génèrent un coût invisible mais considérable pour l’organisation.
Sans visibilité sur les dépendances, chaque incident devient long à diagnostiquer :
il faut remonter manuellement les pipelines,
identifier les modèles impactés,
comprendre les flux de données,
coordonner plusieurs équipes.
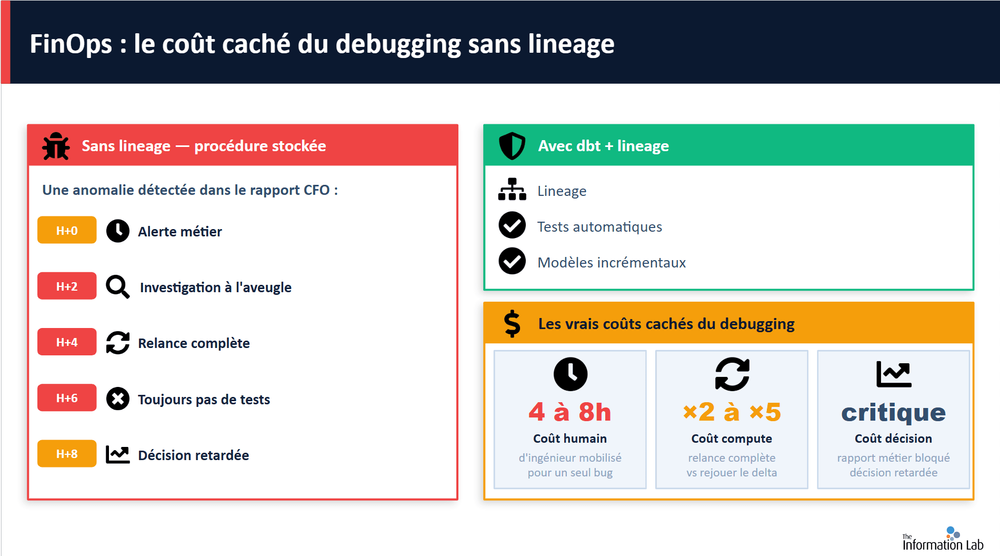
C’est précisément ce que le lineage de dbt Labs permet de simplifier.
En centralisant les dépendances et les relations entre modèles, sources et dashboards, dbt réduit fortement le temps nécessaire pour comprendre, isoler et corriger un problème.
L’impact FinOps est alors beaucoup plus large qu’une simple optimisation compute :
moins de temps perdu en investigation,
moins d’interruptions métier,
une meilleure gouvernance des pipelines,
et une plateforme plus simple à maintenir dans le temps.
Au final, une stratégie FinOps mature ne consiste pas uniquement à réduire les coûts techniques.
Elle vise surtout à améliorer l’efficacité globale de la plateforme et des équipes qui la font vivre.
5 pratiques dbt pour construire une gouvernance FinOps durable
1. Réduire les traitements inutiles dès le départ
Une grande partie des coûts provient de pipelines qui recalculent des modèles alors qu’ils n’ont pas changé. Avec Slim CI, dbt Labs ne reconstruit que les éléments impactés par une modification, ce qui évite les exécutions complètes et optimise directement l’usage des ressources.
2. Donner un owner à chaque modèle
Un modèle sans responsable devient rapidement un coût difficile à piloter. En définissant un owner dans dbt, chaque asset est rattaché à une équipe ou un usage métier, ce qui rend les coûts plus lisibles et facilite la responsabilisation.
3. Aligner les runs sur les données
Beaucoup de pipelines tournent encore selon des horaires fixes, même sans évolution des données. dbt permet de déclencher les traitements uniquement lorsque les données changent réellement, ce qui limite les exécutions inutiles et améliore l’efficacité globale.
4. Faire du FinOps un sujet collectif
Le FinOps ne peut pas être uniquement technique. Les revues régulières entre équipes data et métier, appuyées par le lineage dbt, permettent de relier les coûts aux usages réels et de mieux comprendre la valeur des pipelines.
5. Mesurer les gains
Sans mesure, une optimisation n’a pas de valeur réelle. Suivre les temps de traitement, les ressources consommées et les gains obtenus permet de vérifier l’impact des actions et d’ancrer une démarche d’amélioration continue.
Conclusion : FinOps, une discipline avant d’être un outil
Le FinOps ne se résume pas à une optimisation technique ou à un tableau de bord de coûts. C’est avant tout une manière de concevoir et de piloter la data autour de trois principes simples : comprendre ce que l’on dépense, savoir pourquoi on le dépense, et s’assurer que cela crée réellement de la valeur.
Des outils comme dbt Labs aident à rendre cette approche concrète, en apportant de la visibilité, de l’automatisation et de la responsabilité sur les pipelines data. Mais la vraie transformation reste organisationnelle : aligner ingénierie, finance et métier autour des mêmes arbitrages.
Au final, un FinOps efficace n’est pas un projet que l’on termine, mais une culture que l’on installe progressivement dans la manière de construire et de faire vivre la plateforme data.
FAQ — FinOps avec dbt
1. State-Aware Orchestration est-il disponible pour dbt Core ?
Non, SAO nécessite le moteur dbt Fusion qui n'est disponible que sur dbt Cloud (et encore en preview au moment de la rédaction). Pour dbt Core, vous pouvez implémenter une forme simplifiée de state-aware logic en combinant le flag --stateet des sélecteurs personnalisés, mais vous n'aurez pas le cache temps réel ni la gestion automatique des collisions entre jobs.
2. Cost Insights fonctionne-t-il sur tous les warehouses ?
Cost Insights est compatible avec Snowflake, BigQuery et Databricks. Il s'appuie sur les tables système de métadonnées de chaque plateforme (QUERY_ATTRIBUTION_HISTORY pour Snowflake, information_schema.jobs pour BigQuery, system.billing pour Databricks). Si vous êtes sur Redshift, PostgreSQL ou autre, vous devrez construire votre propre instrumentation.
4. Quelle est la différence entre Slim CI et State-Aware Orchestration ?
Slim CI optimise les runs de développement et de CI en ne reconstruisant que les modèles modifiés dans une PR. State-Aware Orchestration optimise les runs de production en ne reconstruisant que les modèles dont les sources ont réellement changé depuis le dernier run. Les deux mécanismes sont complémentaires et se cumulent.
Ressources complémentaires
Documentation officielle dbt : Cost Insights — https://docs.getdbt.com/docs/explore/cost-insights
dbt Labs : 29%+ warehouse savings with dbt Fusion engine — https://www.getdbt.com/blog/dbt-fusion-cost-efficiency
FinOps Foundation : Framework overview — https://www.finops.org/framework/
State of FinOps 2025 Report — https://data.finops.org/2025-report/