
Dans cet article, je vous partage mon retour d'expérience concret sur la migration de systèmes de données legacy vers une modern data stack basée sur le cloud. Après une courte définition de ce qu’est la modern data stack, je vous parlerai des raisons stratégiques de cette transition (sécurité, accessibilité, flexibilité), les défis rencontrés lors de la conversion des anciennes fonctionnalités, ainsi que l'importance cruciale de la collaboration entre les équipes techniques et métiers pour garantir une transformation réussie et pérenne.
Le passage à une modern data stack n'est plus une simple option technique, mais une nécessité stratégique. J'ai pu observer que les systèmes hérités, bien qu'ils aient fait leurs preuves, freinent désormais l'agilité des organisations et exposent les données à des risques de sécurité accrus, car ils sont souvent difficiles à maintenir et peu scalables. La capacité à ingérer et traiter les données rapidement en faisant scaler l’infrastructure proportionnellement à la workload, permet d’optimiser les coûts de fonctionnement en plus d’être un avantage concurrentiel direct. Ce sujet est crucial car il s'agit de transformer une dette technique en une infrastructure d'avenir, garantissant la réactivité et la pérennité de l'entreprise.
La modern data stack
Tout d’abord, qu’est ce que c’est, la modern data stack ? C’est un écosystème de services (en majorité cloud) dont le but est de permettre une meilleure flexibilité tout au long de la chaîne de la data. On y retrouve donc :
Des outils d’Extraction, de Transformation et d’ingestion (Load) qui sont les fameux ETL/ELT (selon l’ordre des opérations)
Des data lake et data warehouse qui permettront de stocker, d’appliquer les transformations et traiter les requêtes vers vos données sur des infrastructures scalables horizontalement comme verticalement (parallélisation et/ou puissance de calcul)
Des orchestrateurs pour maîtriser le déclenchement et les conditions d’exécution de vos différents processus
Des outils d’activation BI, fait pour se connecter à vos data warehouse et vous permettre de visualiser efficacement les signaux de vos data renferment
En bref, la modern data stack, elle a pour but de réduire la complexité de maintenance qui serait liée à une infrastructure self hosted et flexibiliser le traitement de vos workload en vous permettant de scaler vite en “pay as you go”, sans vous soucier de la capacité restante dans votre système. En revanche, dans sa forme la plus aboutie, elle est souvent composée de multiples services.
Migration du système hérité
Les infrastructure cloud peuvent souvent être mise en place assez rapidement. Néanmoins, Il est souvent plus difficile de transférer toutes les fonctionnalités de l'ancien système vers le nouveau. Un des facteurs clés de la réussite d’une telle migration réside comme toujours dans sa planification. Si tout les flux et processus sont documentés avec leurs conditions de déclenchement, trouver les outils qui conviennent le mieux pour votre migration devient de suite plus clair.
Par exemple, pour implémenter une architecture medallion (bronze, silver, gold) dans votre warehouse :
Les appels API pour récupérer les données de vos outils et les charger dans les schémas et tables bronze seront délégués à des services comme Fivetran ou Airbyte
Les anciennes requêtes SQL pourront être refactorisées en modèles dbt pour produire les tables silver et gold. Cela permettra ainsi d’avoir un meilleur lineage de vos data et d’ajouter/modifier des modèles de manière simplifiée.
Si les extractions et mises à jours des modèles ne reposent pas sur de la logique complexe, les orchestrateurs internes de dbt Platform, Fivetran ou Airbyte permettront d’exécuter de façon récurrentes les tâches. Dans le cas de process plus complexes, un orchestateur comme Airflow pourra aisément être utilisé pour intégrer de la logique python dans l’exécution de vos tâches et par exemple, déclencher votre pipeline de data science.
Votre warehouse sera le centre névralgique de tout ces processus. Une fois les service account et roles créés, vous pourrez configurer la puissance alloués à vos services de manière scalable pour être sûr d’upscale en réponse à des pics de charge et garantir que vous ne subirez pas de ralentissement. Les warehouse intègrent aussi des outils de monitoring pour vous avertir et grantir vos budgets en arrêtant automatiquement les workloads qui dépassent vos limites
Enfin, des outils de B.I. se connecteront à votre warehouse pour construire vos tableaux de bords en s’appuyant sur vos tables gold et peut-être aussi votre nouvelle semantic layer.
La clé de la réussite : la collaboration
En tant que consultant chez The Information Lab, j'ai la chance de collaborer avec des organisations pour réaliser ce type de migrations. J'ai remarqué que la réussite de ce processus repose sur une étroite collaboration et beaucoup d'apprentissage mutuel. Le système hérité a souvent été développé sur une longue période et a fait l'objet de nombreux investissements. Il a probablement aussi bien fonctionné pendant de nombreuses années. Il serait dommage que des fonctionnalités et une logique importantes, ainsi construites, soient perdues. L'objectif est de conserver toute la valeur et même de l'étendre !
Un projet de migration peut prendre de très nombreuses formes. J'ai par exemple vécu des situations où j'étais la seule personne à travailler avec une organisation, mais j'ai aussi pu faire partie d’équipe plus grandes avec plusieurs consultants en B.I., des analytics engineer, un chef de projet et un scrum master.
Cela dépend de ce qui est nécessaire, par exemple : la complexité de l'infrastructure requise, la gouvernance à mettre en place et la quantité de données à transférer.
Ces projets de migration sont extrêmement enrichissants ! Répondre aux besoins des métiers tout en respectant les meilleurs pratiques et les contraintes des équipes data est un puzzle complexe qui renferme une grande valeur. Une migration réussie rend la data stack pérenne, simplifie les utilisations de la data et permet une architecture plus flexible sans perdre en qualité.
La modern data stack chez The Information Lab France
De notre côté, nous avons troqué notre base de données on-premise pour Snowflake. Autour, on a choisi Alteryx, Fivetran et dbt Platform pour nos process ETL, Airflow en orchestration et enfin Tableau pour notre B.I. qui repose sur les tables dans Snowflake et la Semantic Layer exposée par dbt Platform.
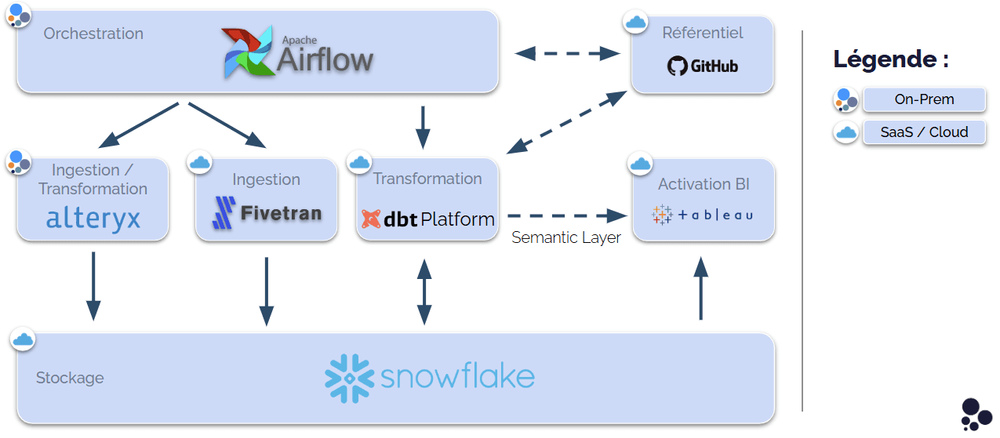
En bref, cette architecture nous a permis de :
Simplifier et accélérer l’intégration de nouvelles sources de données
Créer de nouveaux dashboards plus poussés
Gagner en observabilité sur les différents processus
Améliorer notre monitoring des coûts de fonctionnement
Et enfin : réduire nos coûts
Merci à vous d’avoir lu cet article, j’espère qu’il vous aura aidé à démystifier les enjeux d’une migration vers une modern data stack !
Si votre organisation est confrontée aux défis d'un système legacy et souhaite libérer le potentiel de ses données, je vous encourage à nous contacter directement. Nous serons ravis de vous accompagner vers une solution de données pérenne.
👉 Vous souhaitez aller plus loin ? Contactez-nous à contact@theinformationlab.fr ou explorez nos autres articles sur The Information Lab.