
Les défis des transformations sans dbt
Dans de nombreux projets de data engineering, la gestion des transformations de données s’apparente à une tâche ardue et désorganisée. Les requêtes SQL sont fréquemment dispersées entre plusieurs outils et plateformes : tableaux de bord, notebooks Jupyter, scripts SQL dans des dossiers partagés… Ces fichiers, souvent nommés de manière peu explicite comme rapport_ventes_final_v3.sql, manquent de versionning clair. Les tests de qualité des données sont rares et généralement manuels, tandis que la documentation se limite à quelques commentaires dans le code ou à des fichiers externes vite obsolètes. Cette absence de structure crée une dette technique importante, rendant les mises à jour complexes et risquées. La logique métier manque de transparence, et la confiance dans les données s’effrite, faute de traçabilité sur le calcul des indicateurs ou la fiabilité des résultats.
Le virage vers l’ELT moderne
L’émergence des data warehouses dans le cloud, comme BigQuery, Snowflake et Databricks, a marqué un tournant décisif dans notre approche du traitement des données. Le paradigme ELT (Extract, Load, Transform) a remplacé l’ETL traditionnel. Dans ce nouveau modèle, les données sont extraites de leurs sources, chargées brutes dans le data warehouse à une vitesse fulgurante grâce à la scalabilité du cloud, puis transformées directement dans cet environnement. Cette approche exploite la puissance de calcul des data warehouses modernes, mais elle pose un défi majeur : comment structurer, tester, documenter et maintenir des transformations SQL dans un système aussi flexible ? dbt s’est imposé comme la solution idéale, apportant une méthodologie claire et des outils robustes pour la couche de transformation. En centralisant et en standardisant les processus de transformation, dbt a permis de tirer pleinement parti des capacités du cloud moderne tout en éliminant les approximations des approches précédentes.
Où dbt s’intègre-t-il dans la stack data ?
Dans une architecture ELT, dbt se focalise exclusivement sur la transformation, le "T" du processus. Il ne s’occupe ni de l’ingestion des données, gérée par des outils comme Fivetran, Airbyte ou Azure Data Factory, ni de la visualisation. dbt excelle dans la conversion des données brutes en tables et indicateurs exploitables par les équipes métier, devenant ainsi le cœur battant des pipelines de données. Une chaîne ELT typique commence par l’ingestion des données depuis des sources externes (bases de données, APIs, fichiers) vers un data warehouse. Ensuite, dbt orchestre les transformations pour produire des tables propres et structurées. Enfin, ces données transformées alimentent des dashboards interactifs, des APIs pour des applications, ou des modèles d’apprentissage automatique. En se concentrant sur cette étape centrale, dbt agit comme un pivot qui garantit la cohérence, la fiabilité et la traçabilité des transformations.
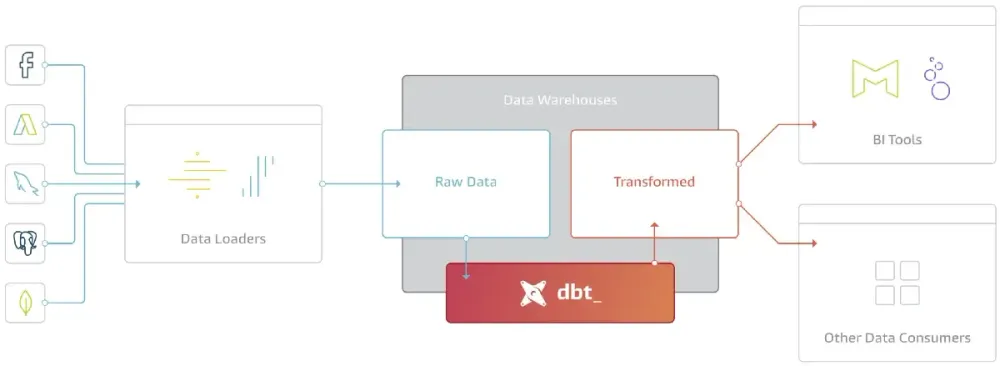
Ce que dbt a changé concrètement
Une structure claire pour des pipelines ordonnés
dbt impose une structure rigoureuse et intuitive pour organiser les transformations. Les données brutes sont d’abord standardisées dans un dossier staging, où elles sont nettoyées et normalisées pour garantir une base cohérente. Les transformations complexes, comme les jointures, les agrégations ou les enrichissements, sont regroupées dans un dossier intermediate. Enfin, les tables finales, prêtes à être consommées par les équipes métier, sont centralisées dans un dossier marts. Prenons l’exemple d’un modèle dans le dossier staging pour une table de commandes :
-- models/staging/stg_orders.sql
{{ config(materialized='view') }}
SELECT
order_id,
customer_id,
order_date,
total_amount,
CASE
WHEN status = 'completed' THEN 'Complete'
ELSE status
END AS normalized_status
FROM {{ source('raw_data', 'orders') }}
WHERE order_date IS NOT NULL
AND total_amount >= 0
Ce modèle extrait les données brutes de la table orders, normalise le champ status pour harmoniser les valeurs, et filtre les lignes invalides (dates manquantes ou montants négatifs). Il est matérialisé comme une vue pour optimiser les performances. Cette organisation claire met fin aux fichiers mal nommés et rend les pipelines lisibles, maintenables et évolutifs, même dans des projets complexes avec des centaines de modèles.
Des tests intégrés pour une qualité garantie
L’un des atouts majeurs de dbt est sa capacité à intégrer des tests de qualité directement dans le workflow, rendant la fiabilité des données systématique. Ces tests sont définis dans des fichiers YAML, permettant de vérifier des contraintes essentielles. Voici un exemple pour un modèle stg_customers :
# models/staging/schema.yml
version: 2
sources:
- name: raw_data
database: my_database
schema: public
tables:
- name: customers
models:
- name: stg_customers
description: "Tableau nettoyé des clients, avec des identifiants et segments standardisés."
columns:
- name: customer_id
description: "Identifiant unique du client."
tests:
- unique
- not_null
- name: customer_segment
description: "Segment de clientèle (B2B, B2C, Enterprise)."
tests:
- accepted_values:
values: ['B2B', 'B2C', 'Enterprise']
- name: email
description: "Adresse e-mail du client."
tests:
- not_null
- dbt_utils.expression_is_true:
expression: "email ~ '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}$'"Ce fichier YAML spécifie que customer_id doit être unique et non nul, que customer_segment ne peut contenir que des valeurs prédéfinies, et que email doit respecter un format d’adresse e-mail valide grâce à un test personnalisé utilisant le package dbt utils. En exécutant dbt test, dbt vérifie ces contraintes et génère des alertes en cas d’anomalie, comme un doublon dans customer_id ou un e-mail mal formaté. Cette approche permet de détecter des erreurs critiques, comme des segments de clientèle incohérents ou des données manquantes, avant qu’elles n’impactent les analyses en aval, renforçant la confiance dans nos pipelines.
Des modèles interconnectés et réutilisables
dbt permet de créer des modèles SQL modulaires qui s’appellent les uns les autres grâce à la fonction ref(), garantissant une gestion automatique des dépendances. Par exemple, un modèle dans le dossier marts pourrait agréger les données de plusieurs modèles staging pour produire des métriques métier :
-- models/marts/customer_metrics.sql
{{ config(materialized='table') }}
SELECT
c.customer_id,
c.customer_name,
COUNT(o.order_id) AS total_orders,
SUM(o.total_amount) AS total_spent,
MAX(o.order_date) AS last_order_date
FROM {{ ref('stg_customers') }} c
LEFT JOIN {{ ref('stg_orders') }} o
ON c.customer_id = o.customer_id
WHERE o.order_date >= DATEADD(month, -12, CURRENT_DATE)
GROUP BY c.customer_id, c.customer_nameCe modèle calcule le nombre total de commandes, le chiffre d’affaires et la date de la dernière commande pour chaque client sur les 12 derniers mois. La fonction ref() garantit que stg_customers et stg_orders sont exécutés avant customer_metrics. dbt construit automatiquement un graphe d’exécution (DAG) qui orchestre l’ordre des transformations, assurant que les dépendances sont respectées. Si un modèle amont est modifié, comme l’ajout d’un nouveau filtre dans stg_orders, les changements se répercutent automatiquement, éliminant les duplications et simplifiant la maintenance.
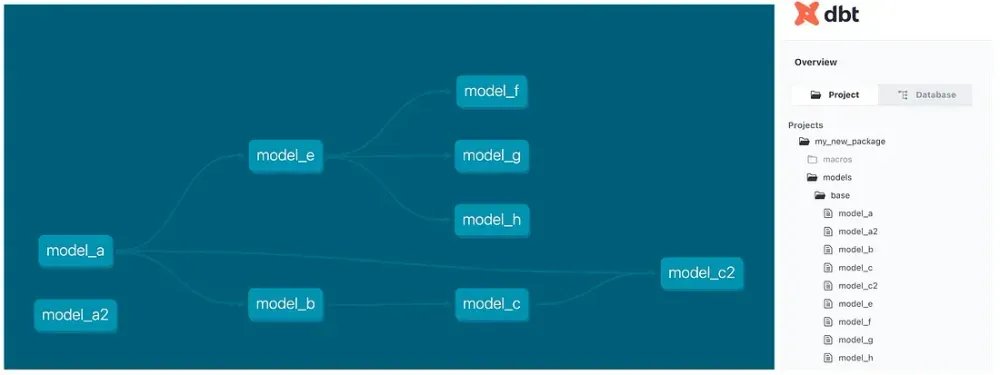
Une documentation intégrée et interactive
La documentation est souvent une tâche négligée. Avec dbt, elle devient un élément central. Chaque modèle et colonne peut être documenté dans le fichier YAML correspondant. Par exemple pour le modèle customer_metrics :
# models/marts/schema.yml
version: 2
models:
- name: customer_metrics
description: "Tableau agrégé des métriques clients, incluant le nombre de commandes et le chiffre d'affaires."
columns:
- name: customer_id
description: "Identifiant unique du client."
- name: total_orders
description: "Nombre total de commandes passées par le client."
- name: total_spent
description: "Chiffre d'affaires total généré par le client."
En exécutant
dbt docs generate
, dbt génère une page interactive qui regroupe le graphe des dépendances (DAG), les tests appliqués, et les descriptions des modèles et colonnes. Cette page, accessible directement dans dbt Cloud via le dbt Catalog, devient une source de vérité partagée. Les Data Engineers y consultent les dépendances techniques pour comprendre l’architecture des pipelines, tandis que les Product Owners valident la logique métier des indicateurs. Cette documentation transparente, intégrée et toujours à jour, a éliminé les malentendus, rendu chaque transformation traçable, et renforcé la collaboration entre les équipes.
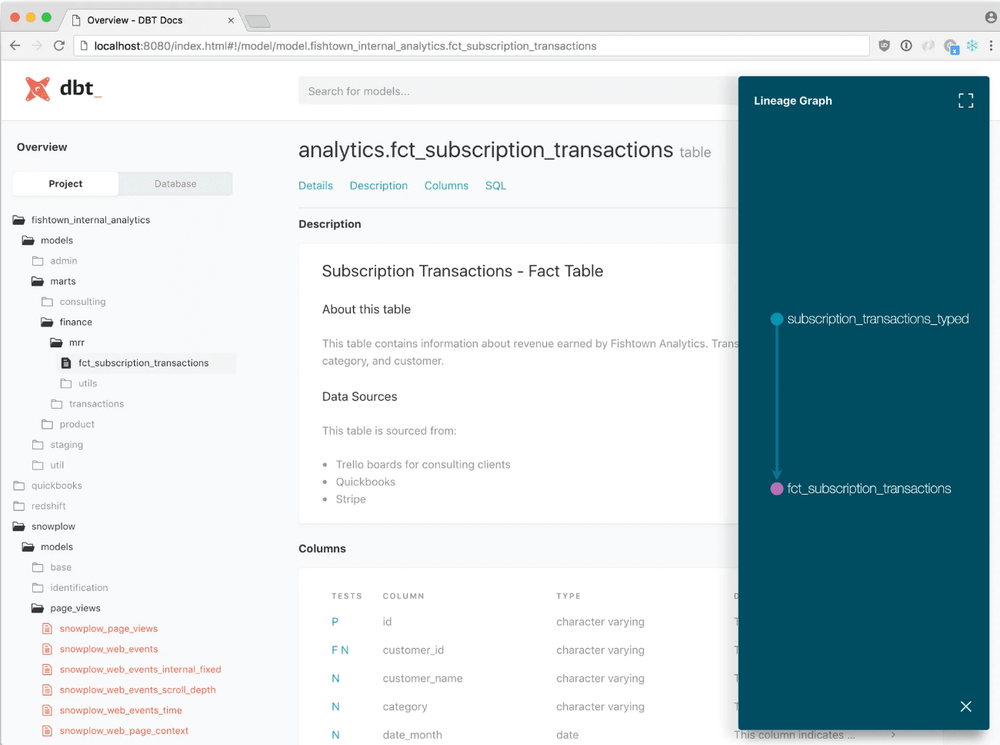
Un versionnement moderne avec CI/CD
dbt s’appuie sur Git, intégrant les meilleures pratiques du développement logiciel au Data Engineering. Chaque modification est soumise via une pull request, revue par les pairs, et versionnée dans l’historique du projet. Les pipelines CI/CD, souvent configurés avec des outils comme GitHub Actions, automatisent les tests et les déploiements. Par exemple, la commande suivante exécute uniquement les modèles modifiés et leurs dépendances downstream :
dbt build --select state:modified+Cette approche réduit le temps de déploiement, minimise les risques d’erreurs en évitant de recompiler l’ensemble du projet, et garantit un code SQL propre et cohérent grâce à des outils comme sqlfluff pour le linting.
Une collaboration fluide entre les rôles
Avant dbt, les Data Engineers, Data Analysts et Product Owners travaillaient en silos. Les Data Engineers construisaient des pipelines ETL complexes, souvent opaques pour les autres. Les Data Analysts, faute d’accès aux transformations, réécrivaient des requêtes SQL dans leurs outils BI, ce qui entraînait des duplications. Les Product Owners manquaient de visibilité sur la logique métier, rendant la validation des indicateurs laborieuse.
dbt a changé la donne en introduisant un workflow collaboratif autour du SQL versionné. Les Data Engineers posent les bases : ingestion, modèles staging, tests de qualité, et pipelines CI/CD. Les Data Analysts contribuent directement aux modèles métier dans le dossier marts, en soumettant leurs modifications via des pull requests. Par exemple, un analyste pourrait créer un modèle pour analyser les ventes par région et par canal de distribution sans avoir à touché aux modèles en amont:
-- models/marts/sales_by_region_channel.sql
{{ config(materialized='table') }}
SELECT
r.region_name,
o.channel,
SUM(o.total_amount) AS total_sales,
COUNT(DISTINCT o.order_id) AS total_orders
FROM {{ ref('stg_orders') }} o
JOIN {{ ref('stg_regions') }} r
ON o.region_id = r.region_id
GROUP BY r.region_name, o.channeldbt a même introduit le rôle d’Analytics Engineer, un profil hybride qui comble le fossé entre les compétences techniques des Data Engineers et les besoins analytiques des équipes métier.
La simplicité extensible de dbt
Malgré sa simplicité apparente, dbt est très flexible et extensible. Par exemple, les macros permettent d’abstraire des patterns SQL répétitifs, rendant le code plus maintenable. Ici on peut visualiser une macro permettant de calculer une moyenne mobile sur les ventes, utilisable dans plusieurs modèles :
-- macros/moving_average.sql
{% macro moving_average(column_name, window_size) %}
AVG({{ column_name }}) OVER (
PARTITION BY region_name
ORDER BY order_date
ROWS BETWEEN {{ window_size - 1 }} PRECEDING AND CURRENT ROW
)
{% endmacro %}Cette macro peut être intégrée dans un modèle pour analyser les tendances régionales :
-- models/marts/sales_trends.sql
SELECT
r.region_name,
o.order_date,
o.total_amount,
{{ moving_average('total_amount', 7) }} AS moving_avg_sales
FROM {{ ref('stg_orders') }} o
JOIN {{ ref('stg_regions') }} r
ON o.region_id = r.region_idLes snapshots permettent de gérer les changements temporels, comme les Slowly Changing Dimensions (SCD). Voici un exemple pour capturer l’historique des modifications dans une table
customers
. Ce snapshot enregistre les modifications des clients au fil du temps, permettant de suivre l’évolution des segments ou des noms.
-- snapshots/orders_snapshot.sql
{% snapshot orders_snapshot %}
{{ config(
target_schema='snapshots',
unique_key='order_id',
strategy='timestamp',
updated_at='updated_at'
) }}
SELECT * FROM {{ source('raw_data', 'orders') }}
{% endsnapshot %}
La communauté dbt propose des packages comme
dbt-utils
, qui offre des utilitaires pour générer des colonnes de hachage, calculer des intervalles de dates, et audit-helper pour comparer des modèles avant et après une mise à jour. Les vérifications de fraîcheur des données (
freshness checks
) garantissent que les sources restent à jour :
# sources.yml
version: 2
sources:
- name: raw_data
database: my_database
schema: public
tables:
- name: orders
description: "Tableau brut des commandes extraites du système ERP."
freshness:
warn_after: { count: 12, period: hour }
error_after: { count: 24, period: hour }
- name: customers
description: "Tableau brut des clients extraites du CRM."
freshness:
warn_after: { count: 6, period: hour }
error_after: { count: 12, period: hour }Cette configuration alerte si les données de la table
orders
n’ont pas été mises à jour dans les 12 heures et génère une erreur après 24 heures, avec des seuils plus stricts pour la table
customers
. dbt s’intègre également à des outils d’orchestration comme Airflow, Azure Data Factory ou GitHub Actions, permettant d’automatiser les transformations dans des pipelines complexes. Par exemple, un DAG Airflow peut orchestrer l’exécution des modèles dbt, les tests de qualité, et la génération de documentation, tout en gérant les dépendances et les notifications en cas d’erreur :
# airflow_dag.py
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.email import EmailOperator
from datetime import datetime
from airflow.utils.trigger_rule import TriggerRule
default_args = {
'owner': 'data_team',
'depends_on_past': False,
'email_on_failure': True,
'email': ['data-team@example.com'],
'retries': 1,
}
with DAG(
'dbt_advanced_pipeline',
start_date=datetime(2025, 1, 1),
schedule_interval='@daily',
default_args=default_args,
catchup=False
) as dag:
dbt_seed = BashOperator(
task_id='dbt_seed',
bash_command='cd /path/to/dbt/project && dbt seed'
)
dbt_run = BashOperator(
task_id='dbt_run',
bash_command='cd /path/to/dbt/project && dbt run --select state:modified+'
)
dbt_test = BashOperator(
task_id='dbt_test',
bash_command='cd /path/to/dbt/project && dbt test'
)
dbt_docs = BashOperator(
task_id='dbt_docs',
bash_command='cd /path/to/dbt/project && dbt docs generate'
)
notify_success = EmailOperator(
task_id='notify_success',
to='data-team@example.com',
subject='dbt Pipeline Success',
html_content='The dbt pipeline completed successfully.',
trigger_rule=TriggerRule.ALL_SUCCESS
)
dbt_seed >> dbt_run >> dbt_test >> dbt_docs >> notify_successConclusion
dbt a révolutionné le Data Engineering en structurant les pipelines SQL avec clarté et rigueur. Ce cadre fluide favorise une collaboration étroite entre Data Engineers, Data Analysts et Product Owners, tout en renforçant la fiabilité et la transparence des données grâce à des tests automatisés et une documentation intégrée. En s’appuyant sur des outils de base comme le SQL, le YAML et Git, dbt a introduit le rôle d’Analytics Engineer, un profil hybride qui allie expertise technique et compréhension des besoins métier, comblant ainsi le fossé entre ces domaines. Loin d’être un simple outil, dbt s’impose comme un standard essentiel qui redéfinit le Data Engineering moderne, le rendant plus robuste, collaboratif et agile. Les pipelines deviennent maîtrisés, les silos s’effacent, et une confiance durable dans les données permet de se concentrer sur la création de valeur.